Welcome to hassangul.com! I’m Hassan Gul. With over 12+ years of experience in full-stack web development and as a top-rated, preferred freelancer on Freelancer.com, I have witnessed multiple tectonic shifts in the digital landscape. From the early rise of responsive design to the complete domination of modern JavaScript frameworks, I’ve helped countless businesses adapt and thrive. However, nothing compares to the massive disruption we are experiencing right now with Artificial Intelligence.
Whether you’re a novice stepping into the world of digital automation for the very first time, or an experienced web designer looking to architect complex, enterprise-grade solutions, one thing is abundantly clear: off-the-shelf software is no longer enough.
Generic AI tools might be great for drafting an email. Still, they fall completely flat when asked to understand your specific business logic, query your private databases, or automate your unique internal workflows. The future belongs to custom-tailored intelligence.
Today, we are focusing on exactly that. We will explore how technical directors and enterprise leaders can leverage APIs to build proprietary AI capabilities into their existing apps and websites. So, without further ado, let’s dive into the definitive guide on Custom AI API Integration and Development, focusing specifically on OpenAI API integration services, enterprise LLM integration, and custom AI plugin development.
Key Takeaways:
- OpenAI API integration services go beyond basic chatbots by using System Prompt Engineering, Retrieval-Augmented Generation (RAG), and Structured Data Outputs to connect foundational models directly to your unique business logic.
- Enterprise LLM integration demands robust, scalable architecture. This includes multi-model routing (dynamically switching among GPT-5o, Claude 4.5, and local models), semantic caching to reduce token costs, and rigorous observability.
- Custom AI plugin development equips language models with the ability to take real-world action—such as querying secure ERPs, modifying inventory, or scheduling appointments—by bridging AI with your internal APIs.
- Data Security is Solved: Leveraging enterprise services like Microsoft Azure OpenAI guarantees your proprietary data never leaves your tenant and is strictly shielded from public model training.
The 2026 Paradigm Shift: Why Generic SaaS is Failing Enterprises:
We are deep into the AI era, and the initial honeymoon phase with public chatbots is over. Enterprise leaders and technical directors frequently approach me with a common frustration: “We have ChatGPT enterprise accounts for our staff, but the AI doesn’t actually know our business.”
Generic SaaS platforms operate in a vacuum. They don’t have access to your real-time inventory, they can’t read your secure internal HR documents, and they certainly cannot trigger actions within your proprietary ERP systems. When businesses rely solely on generic AI solutions, they face several critical bottlenecks:
- Data Silos: The AI operates outside of the company’s core data infrastructure, requiring employees to manually copy-paste context back and forth.
- Hallucinations: Without access to a verified internal knowledge base, LLMs (Large Language Models) are prone to making up answers—a liability no enterprise can afford.
- Workflow Friction: Standalone AI apps force users to switch contexts. In a truly optimized workflow, the AI should come to the user, embedded seamlessly within the CRM, intranet, or customer-facing application they are already using.
To solve these problems, businesses must transition from using AI products to building custom AI capabilities. This transition requires a specialized developer who deeply understands both modern web architecture and cutting-edge machine learning APIs.
Decoding OpenAI API Integration Services:
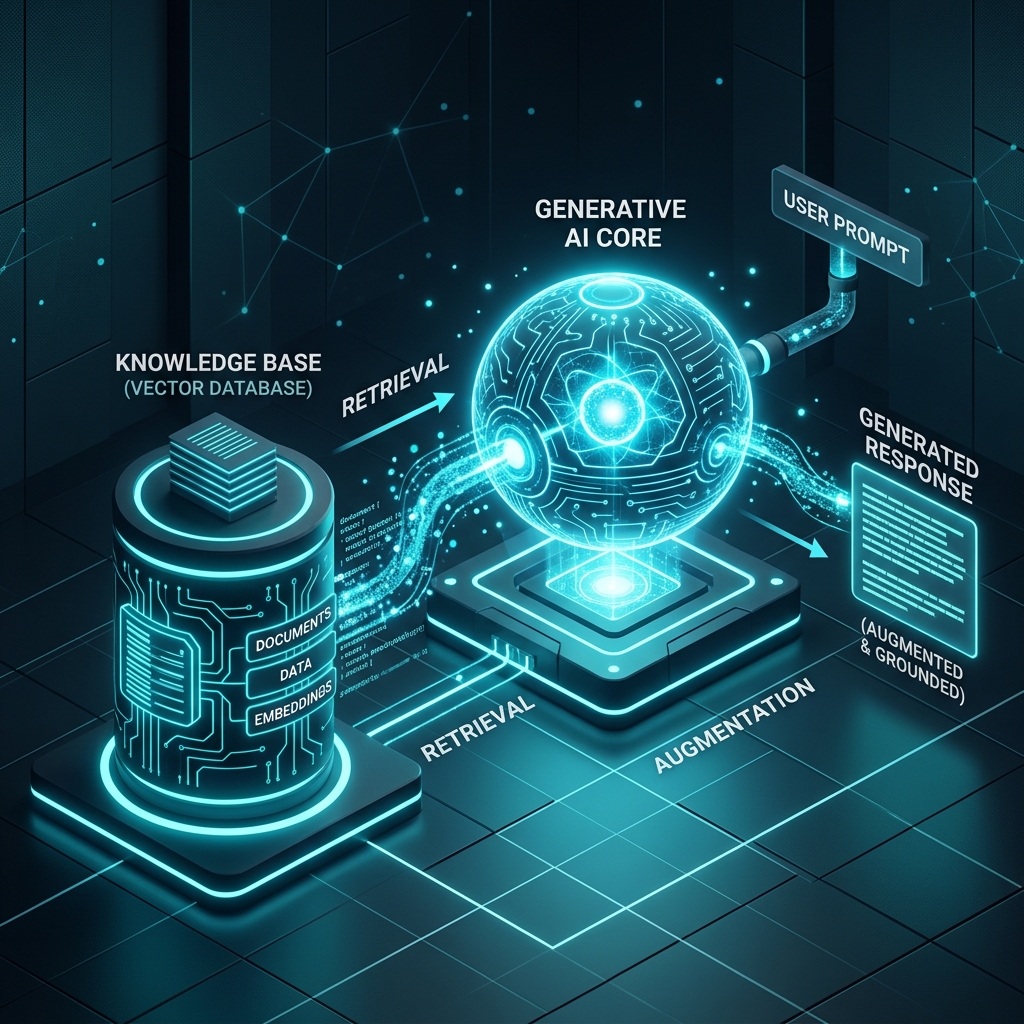
When we talk about OpenAI API integration services, we are talking about far more than just taking an API key and putting a chatbot wrapper on a website. True integration is about bridging the cognitive gap between foundational language models (like GPT-4o) and your specific business logic.
As a web developer, my approach to OpenAI API integration involves several sophisticated layers:
- System Prompt Engineering: Crafting highly specific, dynamic instructions that dictate the persona, constraints, and operational boundaries of the AI.
- Context Window Management: Modern LLMs can ingest massive amounts of text, but sending an entire database with every API call is slow and wildly expensive. Advanced integrations require intelligent context management, ensuring only the most relevant data is sent to the API at any given moment.
- Retrieval-Augmented Generation (RAG): This is the gold standard for OpenAI integration. Instead of relying on the AI’s pre-trained memory, we connect the API to a “Vector Database” containing your private company data. When a user asks a question, the system first retrieves the exact factual documents from your database, feeds them to the OpenAI API, and generates a perfectly accurate, hallucination-free response based solely on your proprietary data.
- Structured Data Outputs (JSON Mode): For enterprise applications, the AI cannot just return conversational text. It needs to return structured data (like JSON) that your web application can parse, store in a database, or use to render user interface elements.
If you are looking to hire a developer for OpenAI API integration services, ensure they are proficient in these advanced techniques, not just basic API fetching.
The Anatomy of Enterprise LLM Integration:
Enterprise LLM integration requires a completely different architectural mindset compared to a simple side project. At the enterprise level, reliability, speed, and model agnosticism are paramount.
Multi-Model Routing
Relying on a single provider (even one as prominent as OpenAI) is a major risk for an enterprise application. Outages happen, API rate limits are hit, and pricing structures change. A robust enterprise LLM integration involves a “Model Router.” This is a middleware layer that dynamically routes requests to the best available model based on the specific task, cost constraints, and current API uptime. For complex reasoning, it might route to OpenAI’s GPT-4o or Anthropic’s Claude 3.5 Opus. For simple, repetitive text classification tasks, it might route to a faster, cheaper model like Gemini Flash or an open-source model hosted on your own servers like Llama 3.
Caching and Cost Optimization
Enterprise applications process thousands of queries per minute. Hitting the LLM API for every single identical query is a massive waste of resources. I always implement Semantic Caching. If User B asks a question that is 95% semantically similar to a question User A asked five minutes ago, the system retrieves the cached answer instantly. This drastically reduces latency and slashes API token costs by up to 60%.
Observability and Analytics
You cannot manage what you cannot measure. Enterprise integrations require deep observability. Every prompt, response, latency metric, and token cost must be logged and monitored. We use tools like LangSmith or custom dashboards to track the AI’s performance, identify failure rates, and continuously refine the system prompts based on real-world user interactions.
Custom AI Plugin Development: Bridging the Gap:

If RAG gives your AI a “memory,” then custom AI plugin development gives it “hands.”
Also known as “Function Calling” or “Tool Use,” custom AI plugins allow the language model to reach out into the digital world and take concrete actions on your behalf. This is where the magic of automation truly happens.
Imagine an internal Slack bot for your HR department. Without custom plugins, the bot can only answer generic questions about company policy. With custom AI plugin development, the bot can:
- Query the real-time BambooHR API to check an employee’s PTO balance.
- Connect to Google Calendar to find an open time slot for a performance review.
- Send an automated email via SendGrid to schedule the meeting.
As a web developer, building these plugins requires creating secure API endpoints on your server that the LLM can “call” when it recognizes the need to perform an action. The AI formulates the correct parameters (e.g., “employee_id: 4852”, “action: check_balance”), sends the payload to my custom-built plugin endpoint, and my code executes the database query. The result is then fed back to the AI to summarize for the user.
Whether it’s creating custom Shopify plugins that allow AI to process refunds, or real-estate plugins that allow AI to schedule property viewings directly into a CRM, custom AI plugin development is the ultimate tool for automating complex workflows.
Core Use Cases for Custom AI Architectures:
To make this tangible, let’s explore how different industries are utilizing custom AI API integration services right now.
- B2B E-Commerce & Wholesale: Instead of a traditional search bar, enterprise e-commerce platforms are deploying AI-driven procurement assistants. Buyers can type, “I need 500 units of heavy-duty brass fittings that meet ISO-9001 standards, and can be shipped to Chicago by Tuesday.” The AI, integrated with the ERP and logistics APIs via custom plugins, instantly checks inventory, calculates shipping, and generates a custom quote.
- Legal & Compliance Firms: Law firms sit on mountains of unstructured data. Through Enterprise LLM integration utilizing complex RAG pipelines, attorneys can query decades of case files instantly. “Summarize all precedents regarding intellectual property disputes in the SaaS sector from our 2023 cases.” The AI retrieves the exact documents, provides citations, and generates a comprehensive brief in seconds.
- Healthcare & Telemedicine: Patient triage and scheduling are major bottlenecks. Custom AI integrations can securely interact with patients via a portal, assess symptoms against medical guidelines (using highly constrained system prompts to avoid medical advice liability), and use plugin development to book appointments into the clinic’s EMR (Electronic Medical Record) system.
- Software Development Agencies: As a freelancer on Freelancer.com, I use custom internal tools to automate my own workflow. I have integrated LLMs with my project management software (Jira/Trello) and GitHub. My custom AI assistant reviews pull requests, drafts release notes, and updates client task boards automatically.
Technical Architecture: The Developer’s Blueprint:

How do we actually build this? For the technical directors reading this, here is a high-level look at the architecture I deploy for my clients:
- The Frontend (User Interface): Usually built with React.js, Next.js, or Vue.js. This is where the user interacts with the AI. It features streaming responses (Server-Sent Events) so the user sees the text typing out in real-time, greatly improving perceived performance.
- The Application Server (Middleware): Built with Node.js/Express or Python/FastAPI. This server securely holds the API keys. Never put OpenAI API keys in the frontend code! This layer handles user authentication, rate limiting, and business logic.
- The Orchestration Layer: We use frameworks like LangChain or LlamaIndex to manage the complex flow of data between the LLM, the vector database, and custom plugins.
- The Vector Database: To facilitate RAG, we use specialized databases like Pinecone, Weaviate, or PgVector (PostgreSQL). Your proprietary data is chunked, converted into numerical vectors (embeddings), and stored here for lightning-fast semantic search.
- The LLM APIs: The external services (OpenAI, Anthropic) that process the prompts and return the intelligent output.
Building this architecture correctly from day one ensures that the system is scalable, secure, and maintainable.
Navigating Data Privacy, Security, and Compliance:
When dealing with enterprise data, security is non-negotiable. The biggest hesitation enterprise leaders have regarding AI integration is data leakage. “Will OpenAI train its public models on my proprietary company data?”
The answer, when integrated correctly, is no.
When you use the standard ChatGPT web interface, your data may be used for training depending on your settings. However, when you utilize OpenAI API integration services, OpenAI’s strict API data privacy policy applies. By default, any data sent through their paid API is not used to train their models, and is retained for a maximum of 30 days solely for abuse monitoring.
For enterprises requiring extreme compliance (HIPAA, SOC2, GDPR), we bypass the public OpenAI API entirely. Instead, we architect the solution using Microsoft Azure OpenAI Service. This provides the exact same GPT models but hosted within your company’s secure Azure cloud environment. It features private networking (VNet), custom encryption keys, and guarantees that your data never leaves your tenant.
Additionally, as a developer, I implement strict RBAC (Role-Based Access Control) within the AI architecture. If a junior employee asks the AI about executive salaries, the RAG system checks the employee’s permission level and blocks the retrieval of restricted documents before the LLM is even invoked.
Pricing and Cost Breakdown for AI Integration:
One of the most frequent questions I receive on Freelancer.com is, “How much does custom AI plugin development or enterprise LLM integration cost?”
Unlike traditional software development, AI integration has both upfront development costs and ongoing operational (consumption) costs. Here is a transparent breakdown:
Upfront Development Costs
- Basic API Integration (Wrapper/Simple Chatbot): 2,500−5,000. Best for small businesses needing basic automated customer service using public knowledge.
- Custom RAG Implementation (Private Data Chat): 8,000−15,000. Involves setting up Vector databases, data ingestion pipelines, and complex prompt engineering.
- Enterprise AI Plugin Architecture: $20,000+. Deep integration into existing ERP/CRM systems, multi-agent workflows, custom function calling, and rigorous security audits.
Ongoing Operational Costs
- LLM API Token Costs: You pay per word (token) processed. For heavy enterprise use, expect anywhere from 100to2,000+ per month depending on volume and the model used (e.g., GPT-4o is more expensive than GPT-3.5 or Gemini Flash).
- Vector Database Hosting: 70−300+ per month for enterprise-grade managed services like Pinecone.
- Server/Cloud Infrastructure: Standard AWS/Azure/GCP hosting costs for your middleware.
Investing in a seasoned developer upfront will save you thousands of dollars in ongoing token costs through proper optimization, caching, and smart model routing.
FAQ:
As search engines evolve into Answer Engines (like Google’s AI Overviews), optimizing for direct questions is crucial. Here are the top questions regarding custom AI integration:
What is the difference between an AI API wrapper and custom AI integration?
An AI API wrapper simply forwards user text to an AI provider and returns a generic response, whereas custom AI integration connects the AI to private databases, executes complex internal workflows via plugins, and enforces enterprise-grade security protocols.
What is the difference between an AI API wrapper and custom AI integration?
An AI API wrapper simply forwards user text to an AI provider and returns a generic response, whereas custom AI integration connects the AI to private databases, executes complex internal workflows via plugins, and enforces enterprise-grade security protocols.
Can custom AI plugins connect to my legacy, on-premise database?
Yes, custom AI plugins can connect to legacy databases through secure VPN tunnels and custom middleware APIs that safely query on-premise servers and translate the retrieved data into a format the Large Language Model can process.
How long does enterprise LLM integration take?
A proof-of-concept for enterprise LLM integration typically takes 2 to 4 weeks to build, while a full-scale, secure deployment with custom plugins and robust data pipelines usually requires 2 to 4 months of dedicated development time.
Is it better to fine-tune a model or use Retrieval-Augmented Generation (RAG)?
For 95% of enterprise use cases, Retrieval-Augmented Generation (RAG) is superior to fine-tuning because RAG provides perfectly accurate, hallucination-free answers based on your live data, whereas fine-tuning is expensive, slow to update, and more prone to factual errors.
Conclusion & Next Steps:
The gap between businesses that utilize generic AI tools and businesses that integrate custom AI into their core infrastructure is widening every single day. Custom AI API integration services, specialized enterprise LLM architecture, and custom AI plugin development are not just buzzwords—they are the foundational building blocks of the next generation of web applications.
Whether you’re a novice to AI technology or an experienced technical director ready to overhaul your internal systems, the time to build is now. By bypassing the limitations of SaaS, securing your proprietary data, and enabling intelligent automation through custom development, you position your business for unprecedented scalability.
Ready to build something extraordinary?
As a top-rated Freelance web developer with over a decade of experience building robust, scalable applications, I specialize in bridging the gap between complex AI technologies and practical business needs.
Let’s discuss how we can integrate a custom AI solution tailored perfectly to your enterprise. Contact me today to schedule a technical discovery call, and let’s bring your vision to life.
To learn more about my services, explore my portfolio on Freelancer.com or check out other technical deep dives here on hassangul.com.
{kind=link}